Introduction: The search for nearest neighbors in a high-dimensional database is complicated by the size of the database and the dimensionality of the space. While in principle the exact nearest neighbors (defined/decided through some distance metric) of a query point are desirable, one often questions the meaningfulness of the search results. This is because for one, the choice of feature vectors is in no way perfect. Different features are useful in different settings. For another, canonical distance measures are poor estimators of perceptual similarity. This has led to the concept of an approximate nearest neighbor or approximate similarity. Instead of incurring the high cost of searching for the exact nearest neighbors, we now have a faster search which returns database points that are close to the query point, but are not necessarily the closest possible. The loss in accuracy (w.r.t some distance metric) is traded against the reduction in the number of elements that need to be scanned or an increase in search speed.
Popular search methodologies either aim at reducing the number of retrieved elements while extracting full information about each of them i.e. retrieved set reduction e.g. clustering-based indexes or aim at reducing the amount of information retrieved about each element, while extracting some information from all database elements i.e. retrieved information reduction e.g. Vector Approximation (VA)-File. An important component of the research work was the study of the applicability of a variety of tools, mostly inspired by signal compression, to approximate similarity search in databases.
|
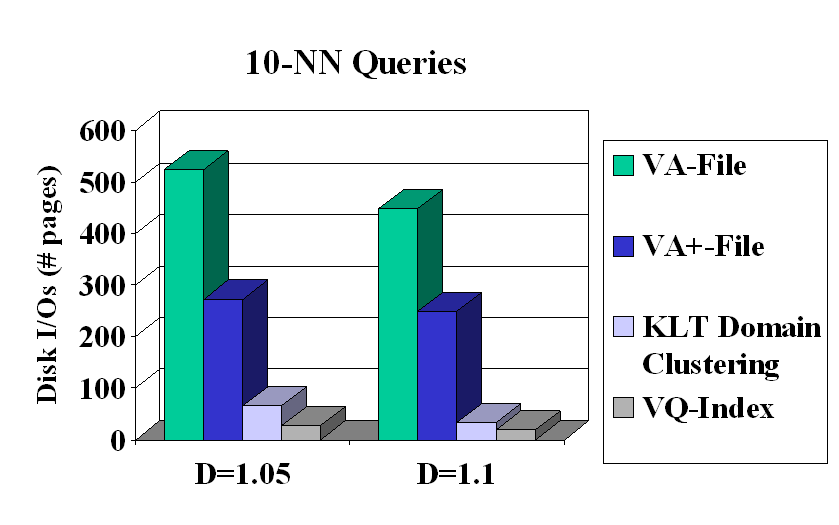
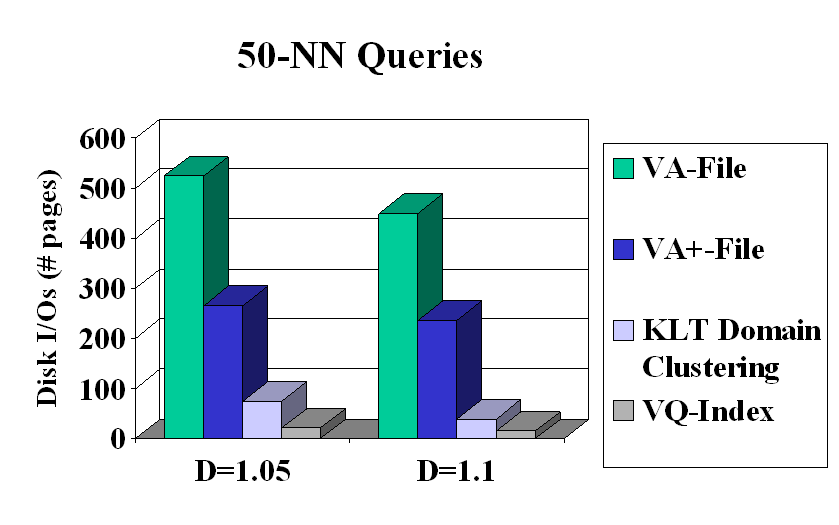
An Index for Fast Approximate Search - the VQ-Index: The VA-File is a powerful technique to counter the so-called 'curse of dimensionality', and is based on scalar quantization. Since it is based on scalar quantization, it does not exploit correlations and dependencies across dimensions. A Vector Quantization (VQ) technique would be able to exploit such dependencies and hence result in a smaller and more compact approximation (representation) of the database. VQ-Index, an index based on VQ, was proposed for approximate similarity search, where accuracy, measured through a soft-variant of the popular recall metric, was traded-off against the number of page accesses (see publication no. 3). Preprocessing storage was controlled through structural constraints on the VQ, namely split and multi-stage vector quantization. This resulted in disk IOs reduced by factors ranging from 26X to 35X over the VA-File, when evaluated on real data-sets.
Fig. 1 Performance comparison of the VQ-Index with other popular indexing techniques (10 Nearest Neighbors mined)
Fig. 2 Performance comparison of the VQ-Index with other popular indexing techniques (50 Nearest Neighbors mined) Trading Search Quality for Search Time - the Rate-distortion Viewpoint: Additionally, the optimality of any search strategy would also depend on the usage i.e. query statistics. A characterization of the the trade-off between search quality and search time (see publications no. 1, 3 and 5 ), where the database designer has access to the query statistics, was studied. An alternate view of similarity search as a guessing game, linked similarity search to an important problem in compression theory, namely successive refinement and the method of types (see publications no. 6 and 9). As a result of this observation, the optimal search strategy was found to be to sort type classes P in increasing order of RP(D), and create the guessing list as the concatenation of codebooks (i.e., sets of codevectors) that cover type classes P1; P2;P3, etc. Combining Retrieved Set Reduction and Retrieved Information Reduction: We have investigated the possibility of effectively combining quantization methods with clustering methods to enjoy benefits from both approaches. Traditionally, vector quantization schemes and clustering schemes both involve a set of representatives or codevectors and the nearest neighbor partition induced by these representatives, and often optimize similar criteria. However, from the database perspective, there is an important difference in the operational framework: given a set of data points, the quantization system stores mappings from the points to their representatives while clustering schemes store the inverse mapping. Since in any reasonable quantization/clustering scenario it is a many-to-one mapping from points to representative, it is advantageous to organize the data using the clustering rather than the quantization paradigm. Hence, while methods for approximate nearest neighbor search will benefit from both compression and clustering techniques as has been demonstrated in our results, it is beneficial to embed them within the clustering framework. Exploiting Query Statistics and Global Optimization:
In practice, each database is subject to a certain usage
pattern or query distribution relevant to its application. When query
statistics, abstracted by a query training set, were incorporated in the
design of our clustering-based search strategy, it provided substantial
improvement in performance to naive clustering techniques (see
publication no. 2). The main features of
such a framework are: i) The contribution of any query to the cost
function involves an explicit tradeoff between the amount of data retrieved for
answering the query and the accuracy with which the query in answered. ii) The
total cost function is averaged over the query distribution. However, the cost
surface is non-convex, leading to the design algorithm getting "trapped" in
locally optimal solutions.
We have been able to formulate a novel design
algorithm based on deterministic annealing, which applies controlled
randomization to the cost function. The mappings are probabilistic and the cost
is minimized subject to a constraint on the system randomness (measured by
Shannon entropy). The level of randomness is gradually reduced in direct analogy
to annealing in physics, thereby avoiding many suboptimal local minima that
would trap greedy techniques. Unlike simulated annealing, the system operates
deterministically by optimizing expectation functionals, rather than simulating
a stochastic process. It is hence considerably faster. Preliminary results show
substantial gains. |