
Description: Substantial activity was devoted this year to the problem of exact nearest-neighbor search in high-dimensional spaces. The Vector Approximation File (VA-File) approach is in fact based on uniform scalar quantization of feature vectors, and is a powerful technique that scales well with size and dimensionality of the data-set. Since feature vectors often exhibit correlations and dependencies across dimensions, one should expect a search technique based on vector quantization to achieve performance gains. Building on our earlier findings that clustering-based search methods are inherently advantageous as the overall framework within which one incorporates compression-based search techniques, and noting that the K-means clustering algorithm is virtually identical to the Generalized Lloyd Algorithm from vector quantization, we designed an indexing technique that competes with VA-File by accurately identifying and retrieving only the necessary clusters.
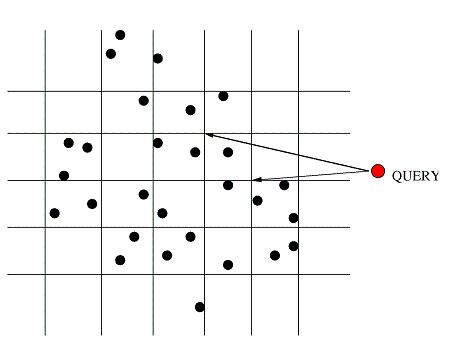
Fig 1: Vector Approximation (VA) -File
The Hyperplane Bound: Central to this index is adaptive bounding of the query-cluster distances. We investigated the effectiveness of known distance bounding methods - namely those based on bounding hyper-rectangles, rotated bounding hyper-rectangles and bounding hyperspheres. This led to and motivated our development of a new and superior bounding technqiue that is based on distance projections onto separating hyperplanes between clusters. We evaluated the performance of our search index over two high-dimensional data-sets and compared it with the known techniques. The data-sets used in our investigation consisted of Gabor feature vectors extracted from aerial photographs (AERIAL - 275,000 elements) and bio-molecular images (BIO-RETINA - 208,000 elements) obtained from the ongoing research work at the Center for Bio-image Informatics, UCSB.
Fig 2: The Hyperplane Bound
Results: We observed that our technique for distance bounding based on separating hyper-planes more effective (than known competitors) in estimating the query cluster distances and in terms of storage overhead (see publication no. 16). Once incorporated in our search index, we observed that the new search index, compared with the VA-File, reduces the number of costly random IO operations by a factor of nearly 100X, for both data sets, given (roughly) the same number of sequential IOs (VA-File at 5 bits/dimension quantization). Our index also incurred nearly 10-100 times less storage overhead as compared with VA-File and was of nearly 10 times lower computational complexity. It provided speed-ups over VA-files (evaluated from 3 bits per dimension to 12 bits per dimension), iDistance and LDC (Local Digital Coding).
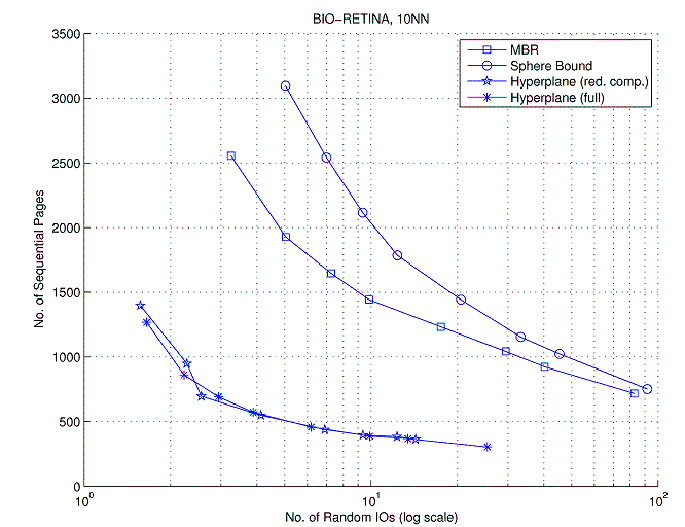
Fig 3: IO comparison Hyperplane Bound vs Sphere and MBR bounds
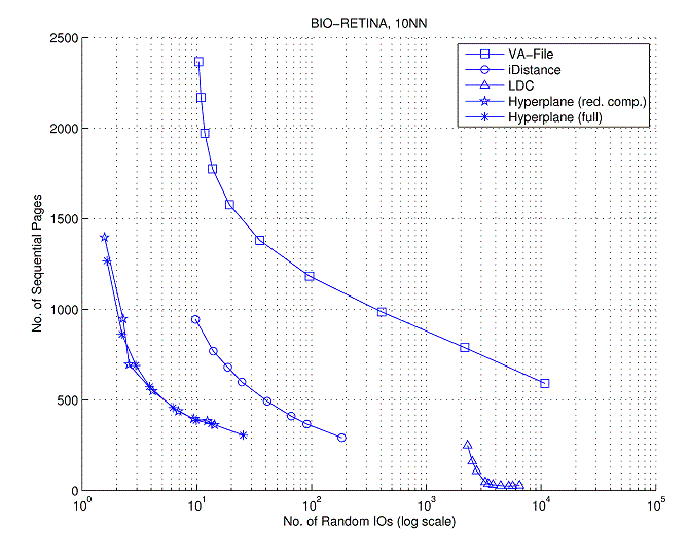
Fig 4: IO comparison VQ-Hyperplane Bounding vs VA-File, iDistance, LDC