

| Jointly Optimized Transform Coding and Spatial Prediction for Video/Image Compression |
|
The overall proposed intra-frame coding scheme, implemented in H.264/AVC framework, switches between derived variant of the sine transform and the conventional discrete cosine transform (DCT), depending on the prediction direction and boundary information. It is experimentally shown to substantially outperform the standard (H.264) intra coding. Moreover, it effectively reduces blocking artifacts, since the transform now adapts to the boundary conditions and better exploits inter block correlations. The perceptual quality is demonstrated on a typical example in Fig. 1. An integer version of the sine transform is also available for deployment in concurrence with the existing integer DCT in H.264/AVC. Related publication: J. Han, A. Saxena, and K. Rose, "Towards jointly optimal spatial prediction and adaptive transform in video/image coding," Proc. IEEE Intl. Conf. Acoustics, Speech, and Signal Processing (ICASSP), Mar 2010. |
| An Estimation-Theoretic Approach to Delayed Video Decoding |
We
propose an estimation-theoretic delayed decoding scheme which
leverages quantization and motion information of one or more future
frames to refine the reconstruction of the current block. Unlike
conventional standard decoders, which reconstruct blocks immediately as
the corresponding quantization indices (as well as motion reference to
a prior frame) are available, the proposed scheme offers optimal
trading off some decoding delay for improved reconstruction.
The method is implemented in the transform domain; and efficiently
combines all available (including future) information in an
appropriately derived conditional probability density function, so as
to obtain the optimal delayed reconstruction of each transform
coefficient in the current block. A complementary fast inverse motion
mapping is also developed to construct the ''motion trajectory'' which
is central to transform domain implementation (Fig. 2). 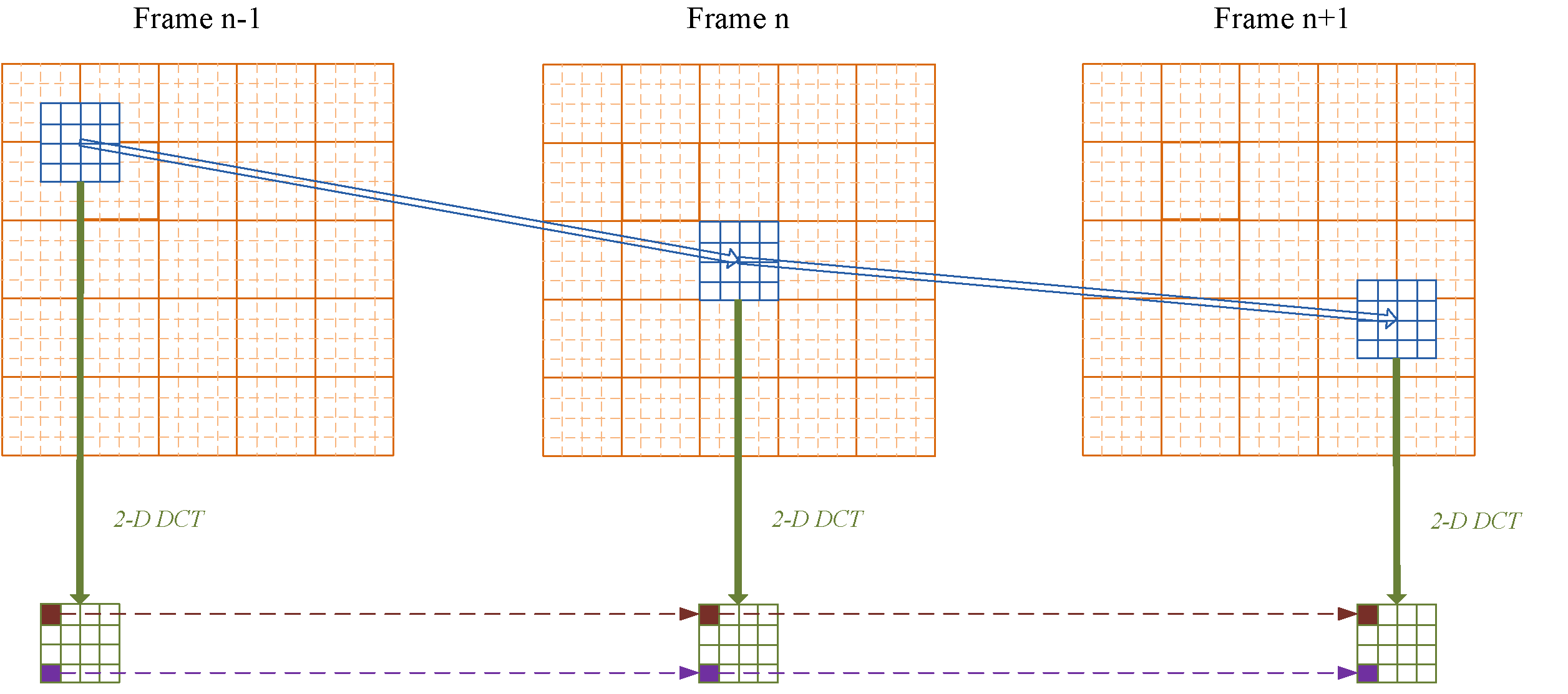 Fig.2
The
proposed
delayed video decoder scheme. The current block (blue in Frame n) is
first connected to its prior and future companions (blues in Frame n-1
and n+1 respectively) to construct the motion trajectory. Each
transform coefficient of the current block is then reconstructed
independently using an estimation-theoretic framework. Fig.2
The
proposed
delayed video decoder scheme. The current block (blue in Frame n) is
first connected to its prior and future companions (blues in Frame n-1
and n+1 respectively) to construct the motion trajectory. Each
transform coefficient of the current block is then reconstructed
independently using an estimation-theoretic framework.Experiments demonstrate substantial gains in terms of the reconstruction quality over the standard H.264 decoder. We emphasize that the proposed delayed decoder only employs information available to the standard decoder, without recourse to side information; hence compatibility with the standard syntax and existing encoders is fully retained. Related publication: J. Han, V. Melkote, and K. Rose, "Estimation-theoretic delayed decoding of predictively encoded video sequences," Proc. IEEE Data Compression Conference (DCC), Mar 2010. |
| Optimal Delayed Prediction in Scalable Video Coding |
Scalable
video coding (SVC) is an important paradigm in many video
networking applications. The base-layer is encoded as an autonomous
bit-stream to enable coarse reconstruction; and refinement is provided
in an enhancement layer that typically employs inter-frame or
inter-layer prediction in the spatial (pixel) domain. An
estimation-theoretic (ET) approach, that optimally combines all
available current base-layer information (captured by quantization
intervals in the transform domain) and enhancement-layer information
via the motion compensated reference, to achieve optimal prediction at
the enhancement-layer, had been developed by our lab. The ET approach
significantly improves the prediction quality and substantially
outperforms other conventional competitors in terms of compression
efficiency. The approach was recently extended to exploit the fact that
the base-layer is encoded independent of the enhancement-layers, and
explore the potential for gains if prediction at the enhancement-layer
is delayed to accumulate and incorporate additional future frame
information from the base-layer. This is optimally performed within the
ET framework. The proposed technique fully exploits all the available
information from the base-layer, including any future frame
information, and prior enhancement-layer information. It achieves
considerable gains over zero-delay techniques including both standard
SVC, and SVC with optimal (zero encoding delay) ET prediction.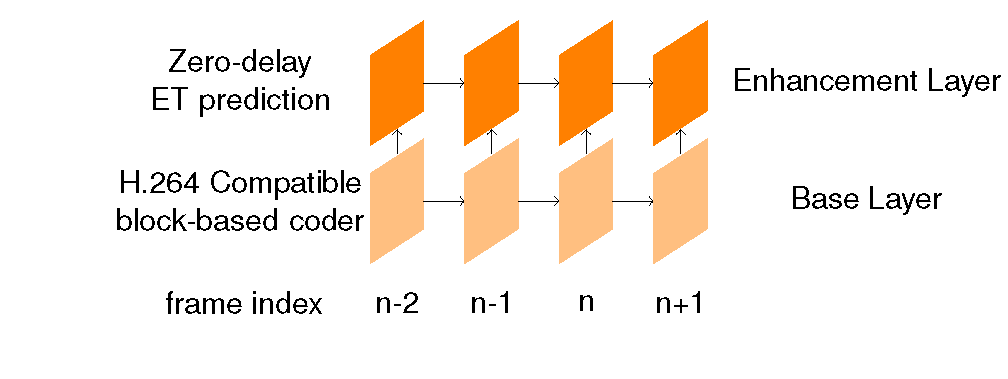
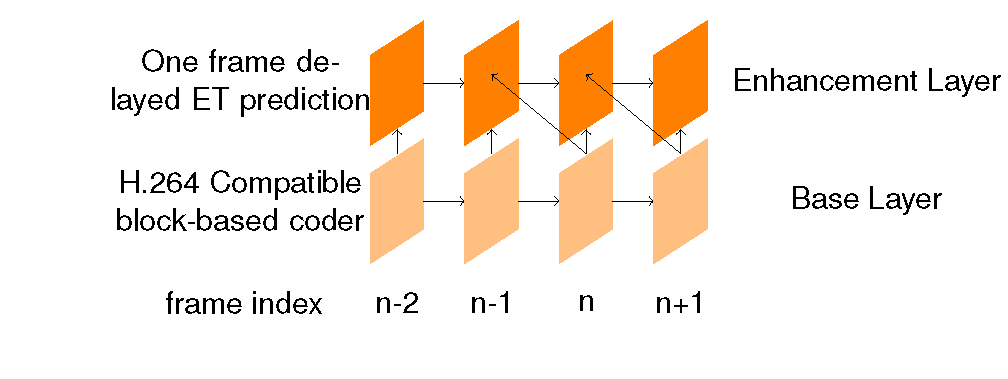
Fig.3 Block diagrams of scalable video coder. The ET with zero encoding delay (left) optimally combines information from past enhancement layer and current base layer. In addition to the casual information, the proposed ET approach with one frame delay at enhancement layer prediction further utilizes future information from base layer. Related publication: K. Rose and S. L. Regunathan, "Toward optimality in scalable video coding", IEEE Trans. Image Processing, 2001. J. Han, V. Melkote, and K. Rose, "An estimation-theoretic approach to delayed prediction in scalable video coding," Proc. IEEE Intl. Conf. Image Processing (ICIP), September 2010. |
|
Coming soon: - Spectral coefficient-wise optimal estimate (SCORE) of end-to-end distortion: a dual technique of ROPE in transform domain. - Transform domain motion-compensated prediction: exploiting the true temporal correlation. For more information, please contact us at jingning at umail ucsb edu. |
 |
|
|