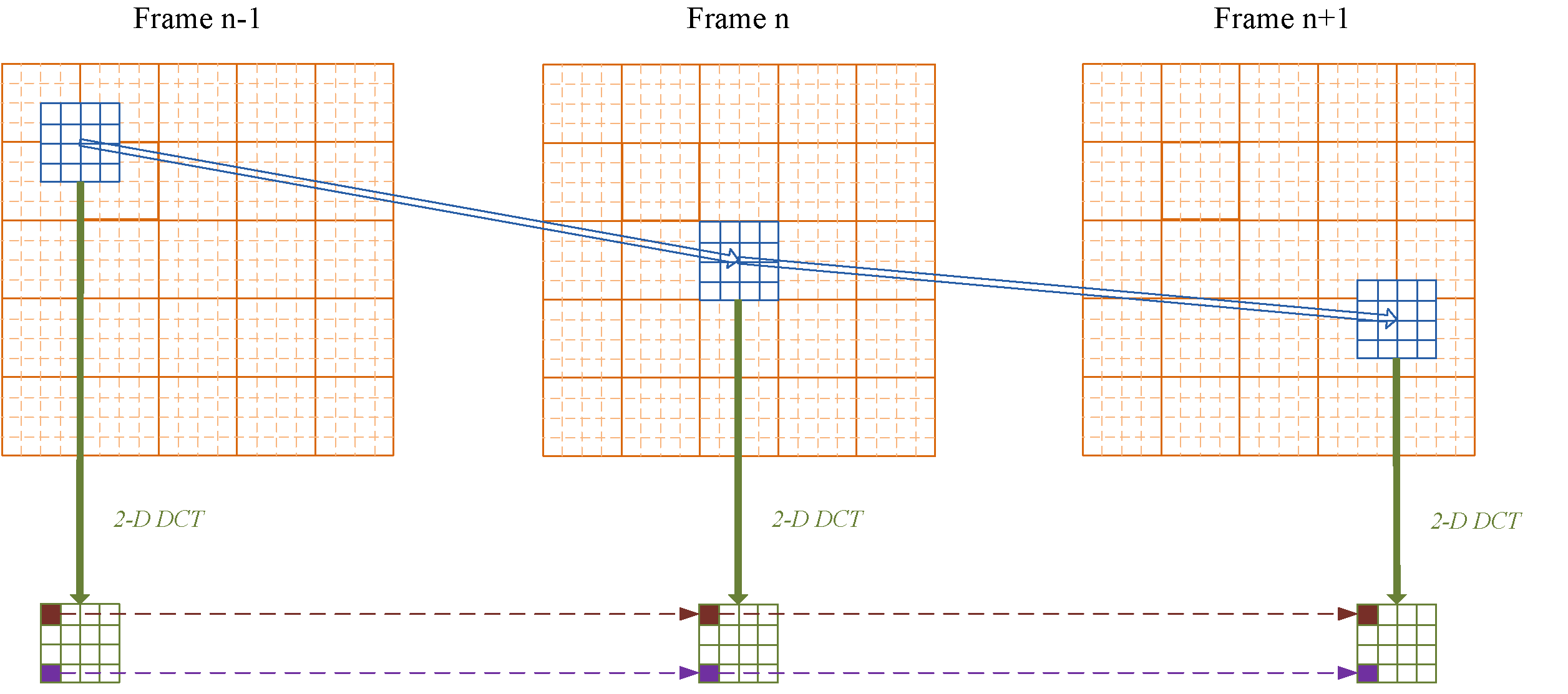
Fig.1 Perceptual quality comparison: The proposed hybrid transform coding scheme (top right) significantly reduces blocking effect and preserves more details, in comparison with DCT (bottom left) and DCT w/ deblocking Filter (bottom right).
A novel approach to jointly optimize spatial context-adaptive prediction (employed as intra mode in H.264) and the choice of the subsequent transform coding is developed for video/image compression. The derived optimal transform for the prediction residual is shown to be a close relative of discrete sine transform, with basis vectors that tend to vanish at the known boundary and maximize energy at the unknown side.
The overall proposed intra-frame coding scheme, implemented in H.264/AVC framework, switches between derived variant of the sine transform and the conventional discrete cosine transform (DCT), depending on the prediction direction and boundary information. It is experimentally shown to substantially outperform the standard (H.264) intra coding. Moreover, it effectively reduces blocking artifacts, since the transform now adapts to the boundary conditions and better exploits inter block correlations. The perceptual quality is demonstrated on a typical example in Fig. 1. An integer version of the sine transform is also available for deployment in concurrence with the existing integer DCT in H.264/AVC.