Immersive auditory experiences can only be achieved by developing techniques to efficiently encode and stream, in a variety of operating conditions, multimedia content formatted to capture information in three-dimensional (3D) space. In this project, we focus specifically on the optimal coding and networking of 3D audio for interactive and immersive applications.
Researchers: Mahmoud Namazi, Ahmed Elshafiy, Sina Zamani
Current video coding standards use trigonometric separable transforms to decorrelate prediction residual in the horizontal and vertical directions. These transforms do not account for the varying statistics of natural video content. In this project, we focus on designing efficient non-separable secondary transforms for prediction residue using the KLT, which helps us further decorrelate the coefficients.
Researchers: Kruthika Koratti Sivakumar
Codebook generation remains an open question in the field of lossy coding where emulating source statistics may not provide good codewords. In this project, we explore the mechanism of natural type selection (NTS) and provide fundamental theoretical limits on the performance for several proposed NTS algorithms.
Researchers: Ahmed Elshafiy, Mahmoud Namazi
360° video is captured on the sphere that encloses the viewer. With increased field of view, 360 video needs significantly higher resolution and thus requires high data rate. Modern video codecs lean heavily on prediction for compression. A simple translation motion model is used in most of the standards which is ineffective for spherical video. The focus of the project is to come up with better motion models on the sphere that would lead to accurate prediction and would reduce the data needed to provide high-quality reconstructed 360 video. (Supported by Interdigital Communications)
Researchers: Bharath Vishwanath, Tejaswi Nanjundaswamy
The main focus of the project is the near optimal design of predictive compression system that accounts for packet loss over unreliable networks. One of the main challenges in the design is the severe non-convexity of the cost function, especially due to the piece-wise linear nature of the quantizer function. We tackle this via a new design approach in the deterministic annealing framework that avoids poor local minima. (This project is partly supported by Mozilla)
Publications:
"Deterministic Annealing Based Design of Error Resilient Predictive Compression Systems", ICASSP 2017 [paper] [poster]
Researchers: Bharath Vishwanath, Tejaswi Nanjundaswamy, Sina Zamani
The hidden Markov model (HMM) is widely used to model processes in several real world applications, including speech processing and recognition, image understanding and sensor networks. A problem of concern is that of quantization of the sequence of observations generated by an HMM, which is referred as a hidden Markov source (HMS). Despite the importance of the problem, and the well-defined structure of the process, there has been very limited work addressing the optimal quantization of HMS, and conventional approaches focus on optimization of parameters of known quantization schemes. In this project we focus on a method that directly tracks the state probability distribution of the underlying source and optimizes the encoder structure according to the estimated HMS status.
Publications:
"On Optimal coding of Hidden Markov Sources", DCC 2014 [paper]
"On Scalable Coding of Hidden Markov Sources", ICASSP 2016 [paper]
Researchers: Mehdi Salehifar, Tejaswi Nanjundaswamy, Emrah Akyol, Kumar Viswanatha
Multimedia content is required at different quality levels due to heterogeneous network conditions and diverse consumption devices. A conventional scalable coder generates a layered bitstream, wherein a base layer produces a coarse reconstruction, and successive layers refine the quality, incrementally. However most multimedia sources are not successively refinable under their relevant distortion metrics. When a source is not successively refinable, conventional scalable coding introduces a performance penalty, while at the other extreme, independent coding is clearly wasteful in resources. As an alternative, we recently proposed a framework with a relaxed hierarchical structure to separate and transmit information common to different quality levels, along with individual bitstreams for each quality level. This framework offers the flexibility to operate at various tradeoff points between conventional scalable coding and independent coding.
Publications:
"Quantizer Design for Exploiting Common Information in Layered Coding", ICASSP 2016 [paper]
"Joint Design of Layered Coding Quantizers to Extract and Exploit Common Information", DCC 2016 [paper]
Researchers: Mehdi Salehifar, Tejaswi Nanjundaswamy
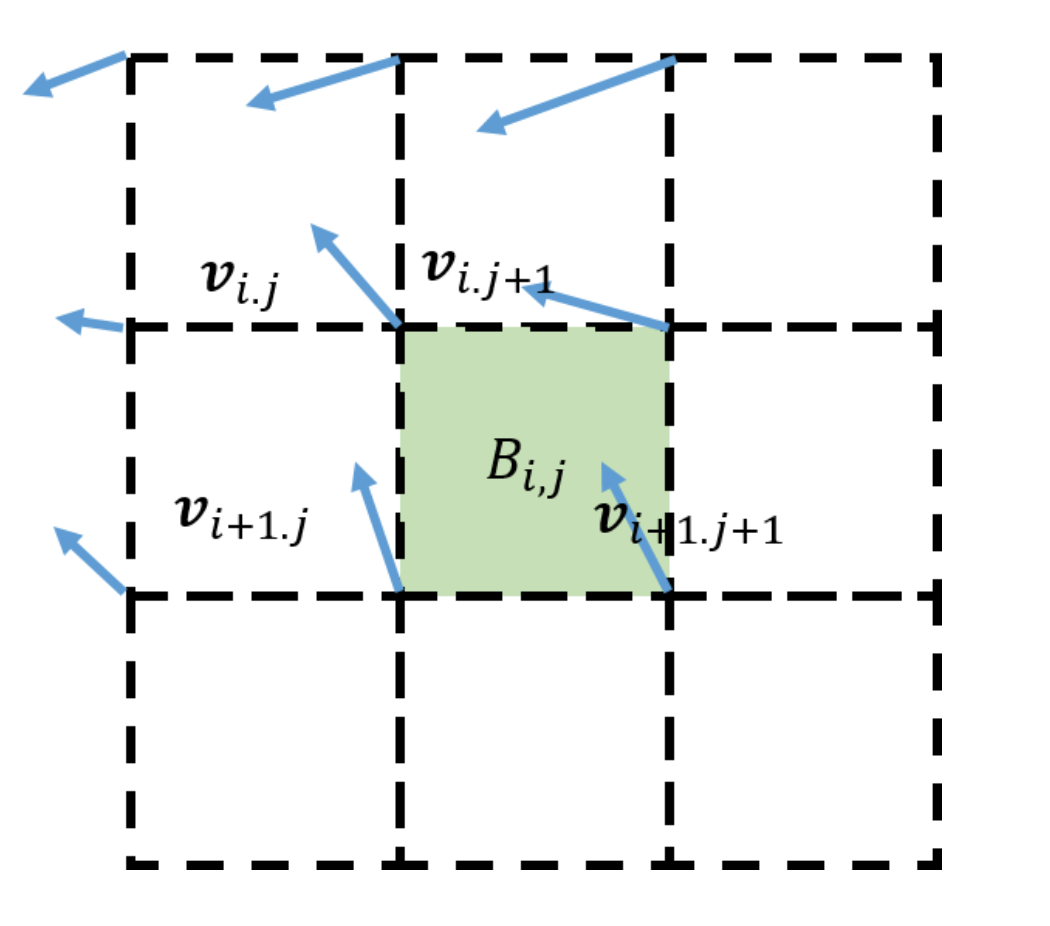
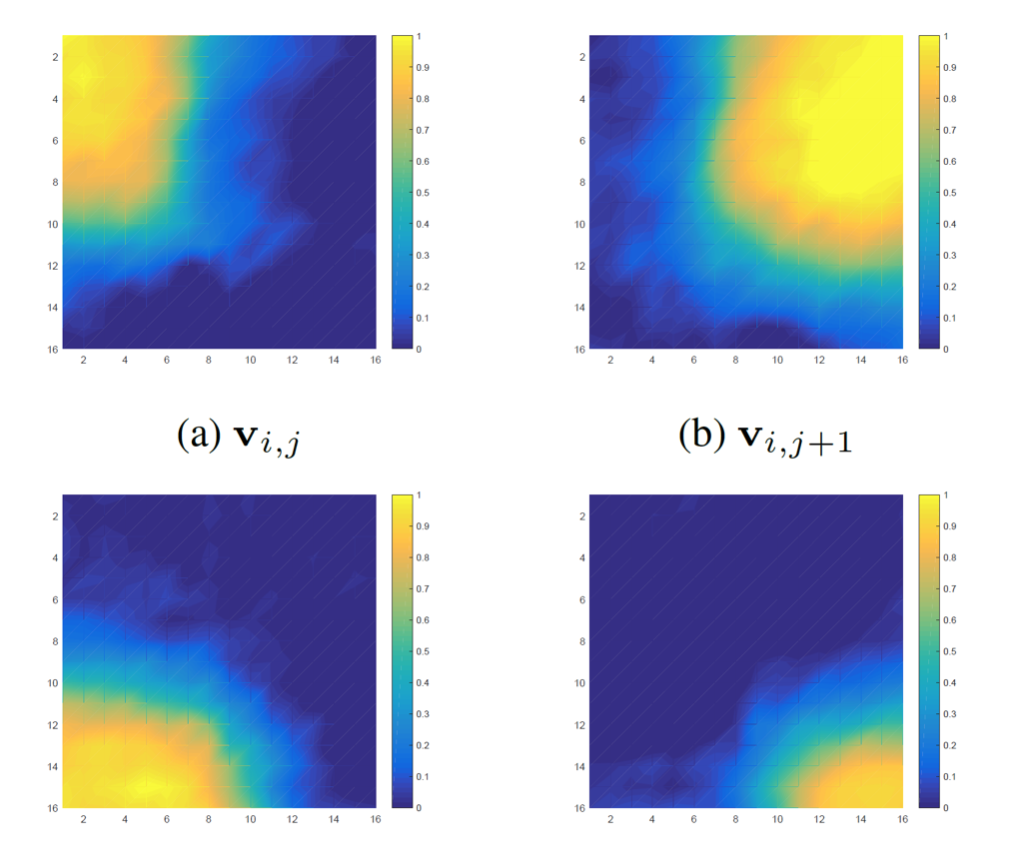
Block-based motion compensation is a key technique targeting to remove temporal redundancy between adjacent video frames while limit the amount of side information to exploit this temporal redundancy, i.e. pixels are grouped into blocks and share the same motion vector. In this block-based motion compensation, every motion vector’s influence is forced to be constant and within a rigid rectangular block structure. Instead we propose a novel paradigm wherein the motion vectors are considered as pointers to multiple observation sources for estimating pixels in the current frame. A non-parametric kernel with a choice of K modes is used to account for the influence of up to 4 motion vectors within a block by interpolating the estimations obtained through the motion vectors. An unsupervised learning is carried out to cluster the estimations from the motion vectors and the non-parametric kernel is optimized to minimize the reconstruction error. (Supported by Google; Have been proposed to the open-source video codec AV1)
 |
 |
|
|
|
Publications:
"Adaptive Interpolated Motion Compensated Prediction", ICIP 2017, to appear
Researchers: Wei-Ting Lin, Tejaswi Nanjundaswamy
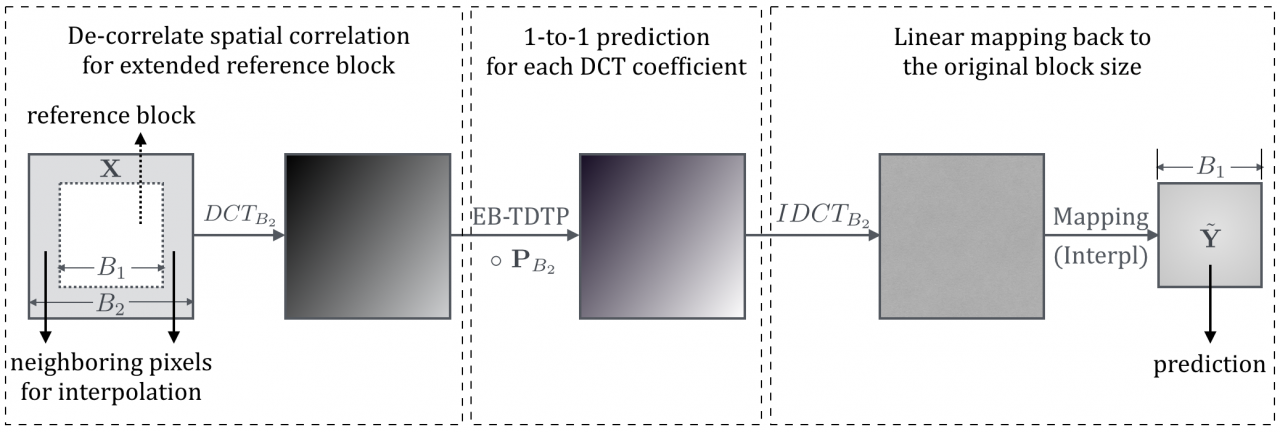
Current temporal prediction relies on motion-compensated pixel-to-pixel copying techniques, which is suboptimal since it ignores the underlying spatial correlation between neighbor pixels. Therefore, we proposed Transform Domain Temporal Prediction (TDTP) where the temporal prediction operates in the transform domain where spatial decorrelation is achieved, which allows for an optimal one-to-one prediction in transform coefficients. It further recognizes the variation in the true temporal correlation across frequencies, which is usually unidentifiable in the pixel domain dominated by low frequencies. Later, we focus on the optimal design of TDTP which: 1) fully exploits spatial correlations both inside and outside block boundary, 2) fully accounts for the coupled interference with sub-pixel interpolation filters, 3) circumvents the challenge of catastrophic design instability due to quantization error propagation through the prediction loop, using Asymptotic Closed-loop (ACL) approach and 4) adapts to local statistics to capture the rich statistics of temporal correlation.
Publications:
"Jointly Optimized Transform Domain Temporal Prediction and Sub-pixel Interpolation", ICASSP 2017 [paper] [slides]
"Transform Domain Temporal Prediction with Extended Blocks", ICASSP 2016 [paper] [poster]
"Asymptotic Closed-loop Design for Transform Domain Temporal Prediction", ICIP 2015 [paper] [poster] [demo]
"Transform-domain temporal prediction in video coding with spatially adaptive spectral correlations", MMSP 2011 [paper]
"Transform-domain temporal prediction in video coding: exploiting correlation variation across coefficients", ICIP 2010 [paper]
Researchers: Shunyao Li, Tejaswi Nanjundaswamy, Bohan Li, Jingning Han, Yue Chen
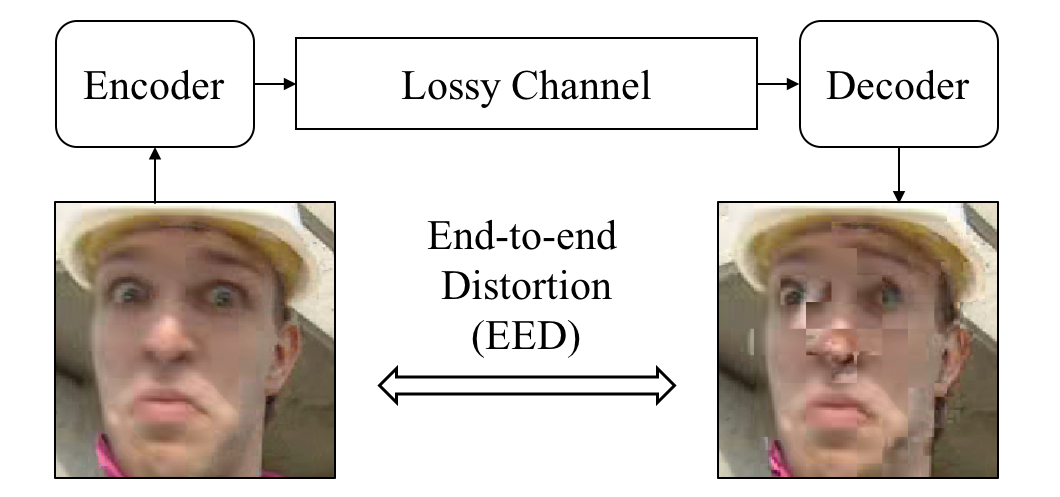
For video streaming via unreliable channels (e.g. wifi networks), many error resilience tools and paradigms have been developed. Typically, these error resilience tools also introduce additional bit-rate costs. The fundamental optimization problem that underlies the coder is then formulated in terms of the trade-off between bit-rate and the distortion perceived at the decoder, also referred to as end-to-end distortion (EED). Clearly, optimization of encoding decisions depends directly on the encoder’s ability to accurately estimate the EED, while accounting for all factors, including compression, packet loss and error propagation due to the prediction loop, and concealment at the decoder.
The recursive optimal per-pixel estimate (ROPE) is a known approach developed by our lab to optimally estimate the distortion by accurately estimate the first and second moments of the decoder reconstructed values recursively. Similar approaches have also been applied in the transform domain and extended to sub-pel motion compensation, variable blocks size, scalable video coding schemes, etc.
Furthermore, a novel error-resilient video coding framework is being developed based on EED estimation. With accurately estimated EED, not only can we optimize current encoder decisions to account for the channel loss, but also develop tools and modes directly designed for this problem and utilize them in the framework. On-going researches are focused on designing a soft-reset prediction mode, with which the trade-off between the error propagation and bit-rate cost can be finer controlled than with the current available prediction tools.
Publications:
"Block-size Adaptive Transform Domain Estimation of End-to-end Distortion for Error-resilient Video Coding", ICIP 2016 [paper]
"A unified framework for spectral domain prediction and end-to-end distortion estimation in scalable video coding", ICIP 2011 [paper]
"A Recursive Optimal Spectral Estimate of End-to-End Distortion in Video Communications", PVW 2010 [paper]
"Advances in recursive per-pixel end-to-end distortion estimation for robust video coding in H.264/AVC", CSVT 2007 [paper]
"Video coding with optimal inter/intra-mode switching for packet loss resilience", J-SAC 2000 [paper]
Researchers: Bohan Li, Tejaswi Nanjundaswamy, Jingning Han, Hua Yang, Rui Zhang
Click to view project archives:
Past Research