Fusion storage and selective retrieval of correlated sources
Research Directions:
Information theoretic analysis of lossless fusion coding
Fusion coder design for storage and selective retrieval
Shared description fusion coding
Predictive fusion coding
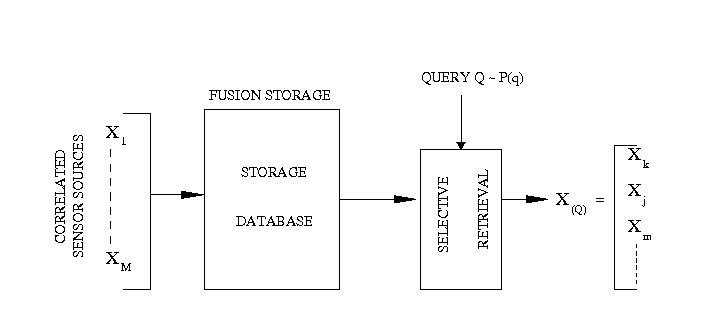
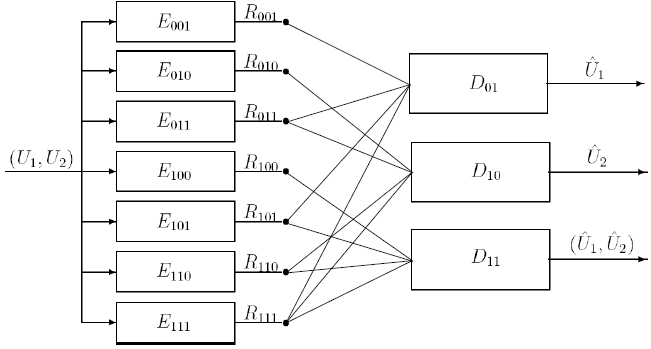
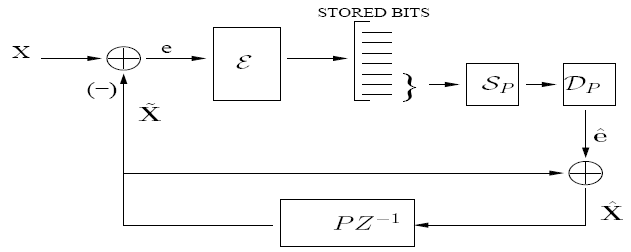
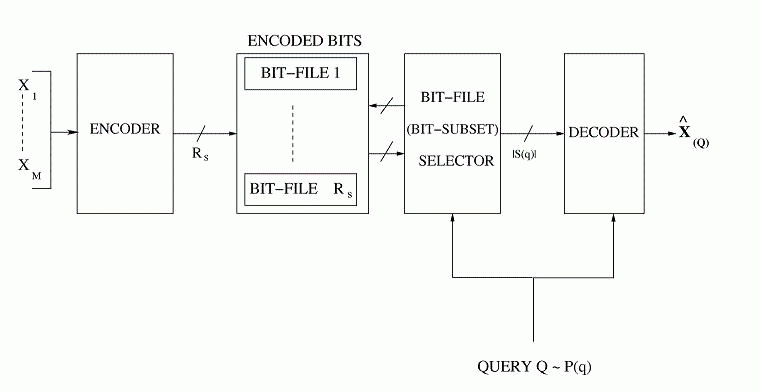 Based on our earlier work on optimized storage and fast selective retrieval of correlated streams of data, we developed information theoretical models that estimate gains possible with selective information retrieval over naive storage techniques. We then formulated a Lagrangian cost function that is a weighted sum of the source and query averaged distortion and the query-averaged retrieval rate, at a given storage complexity. The optimization of this cost over a training set of sample inputs and sample queries reduces to the design of an encoding rule, a mapping from queries to subset of encoded bits and code-books for different subsets of bits. We derived the necessary conditions for optimality and minimized the cost function by iteratively enforcing the necessary conditions for optimality. Since each condition for optimality results in a reduced Lagrangian cost, the algorithm is guaranteed to converge in a few iterations. We investigated the performance of the algorithm over synthetic and real data sets for query distributions representing expected user behavior and compared the results with naive storage techniques - namely joint compression, and separate compression.
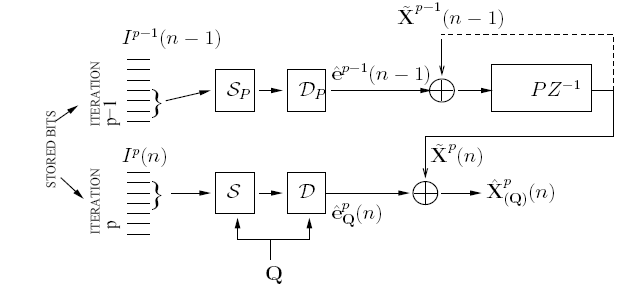
Based on our earlier work on optimized storage and fast selective retrieval of correlated streams of data, we developed information theoretical models that estimate gains possible with selective information retrieval over naive storage techniques. We then formulated a Lagrangian cost function that is a weighted sum of the source and query averaged distortion and the query-averaged retrieval rate, at a given storage complexity. The optimization of this cost over a training set of sample inputs and sample queries reduces to the design of an encoding rule, a mapping from queries to subset of encoded bits and code-books for different subsets of bits. We derived the necessary conditions for optimality and minimized the cost function by iteratively enforcing the necessary conditions for optimality. Since each condition for optimality results in a reduced Lagrangian cost, the algorithm is guaranteed to converge in a few iterations. We investigated the performance of the algorithm over synthetic and real data sets for query distributions representing expected user behavior and compared the results with naive storage techniques - namely joint compression, and separate compression.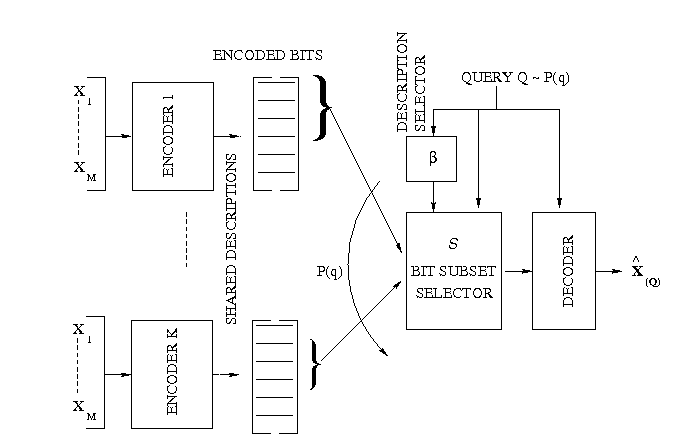 The design complexity of the proposed fusion coder grows exponentially with the storage rate Rs. Hence, the design of practical storage systems that handle hundreds of streams, where it would be necessary to encode streams to a large number of storage bits, would be unfeasible. Structural constraints on the fusion coder would reduce the complexity. One such constrained approach is the shared descriptions fusion coder. Here, queries are mapped to one of several shared descriptions, each generated by a low-complexity (low storage rate) encoder. By iteratively mapping queries to descriptions and designing descriptions that are optimal for the set of queries mapped to them, a constrained version of fusion coder is designed. Note that the constraint is in the fact that while encoders have access to all sources, the bit-selection for a query would be restricted to the bits of the corresponding description. With K shared descriptions, the complexity of design drops to O(K2Rs/K)
The design complexity of the proposed fusion coder grows exponentially with the storage rate Rs. Hence, the design of practical storage systems that handle hundreds of streams, where it would be necessary to encode streams to a large number of storage bits, would be unfeasible. Structural constraints on the fusion coder would reduce the complexity. One such constrained approach is the shared descriptions fusion coder. Here, queries are mapped to one of several shared descriptions, each generated by a low-complexity (low storage rate) encoder. By iteratively mapping queries to descriptions and designing descriptions that are optimal for the set of queries mapped to them, a constrained version of fusion coder is designed. Note that the constraint is in the fact that while encoders have access to all sources, the bit-selection for a query would be restricted to the bits of the corresponding description. With K shared descriptions, the complexity of design drops to O(K2Rs/K)