Audio codecs commonly adopt a transform domain approach where each frame of the signal is transformed to the frequency domain, and the transform coefficients are quantized and entropy coded in the light of a psychoacoustic model. On the other hand speech coders adopt a predictive coding approach, where linear prediction is used to model the vocal tract response/formant information, and subsequently the prediction residual/excitation is coded. Although the general class of audio signals includes speech, in addition to all genres of music and mixed content, audio coders have not been as efficient in coding speech as dedicated speech codecs in terms of the perceptual coding quality at the same bit-rate. This sub-project analyzes why this limitation in audio codecs comes about.
Long term prediction optimized for perceptual audio coders:
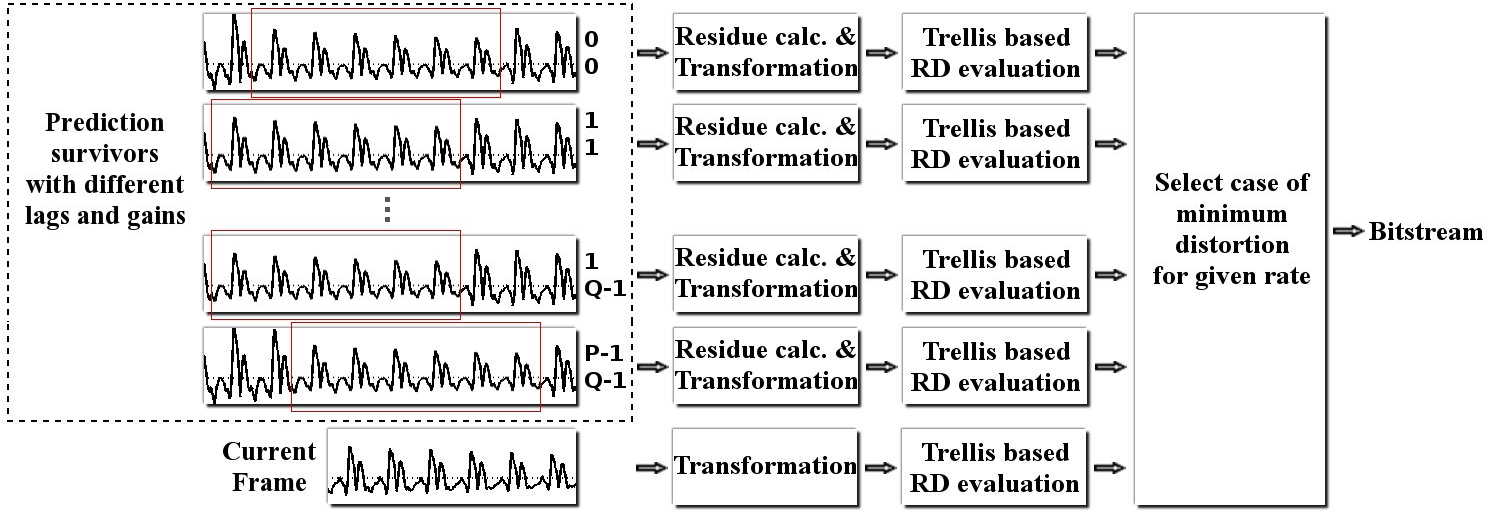
A key aspect of speech coders is that pitch excitation is encoded via long-term prediction (LTP), i.e., prediction is applied across frame boundaries to exploit redundancy due to pitch periodicity. Such periodicity can exist in more generic audio signals too, for example in music with harmonic content. LTP, although available in current audio coding standards as well, is rarely employed. We believe this is because the LTP parameters are typically selected by time-domain techniques aimed at minimizing the mean squared prediction error, which is mismatched with the ultimate perceptual criteria of audio coding. We thus propose a novel trellis-based approach that optimizes the LTP parameters, in conjunction with the quantization and coding parameters of the frame, explicitly in terms of the perceptual distortion and rate tradeoffs. An exhaustive search to find the optimal set is computationally prohibitive, thus the proposed approach reduces the search space by identifying a small set of “prediction survivors” (corresponding to LTP lag-gain pairs), which are then fully evaluated in terms of their RD performance. A low complexity “two-loop” search alternative to the trellis is also proposed. Objective and subjective results provide evidence for substantial gains.
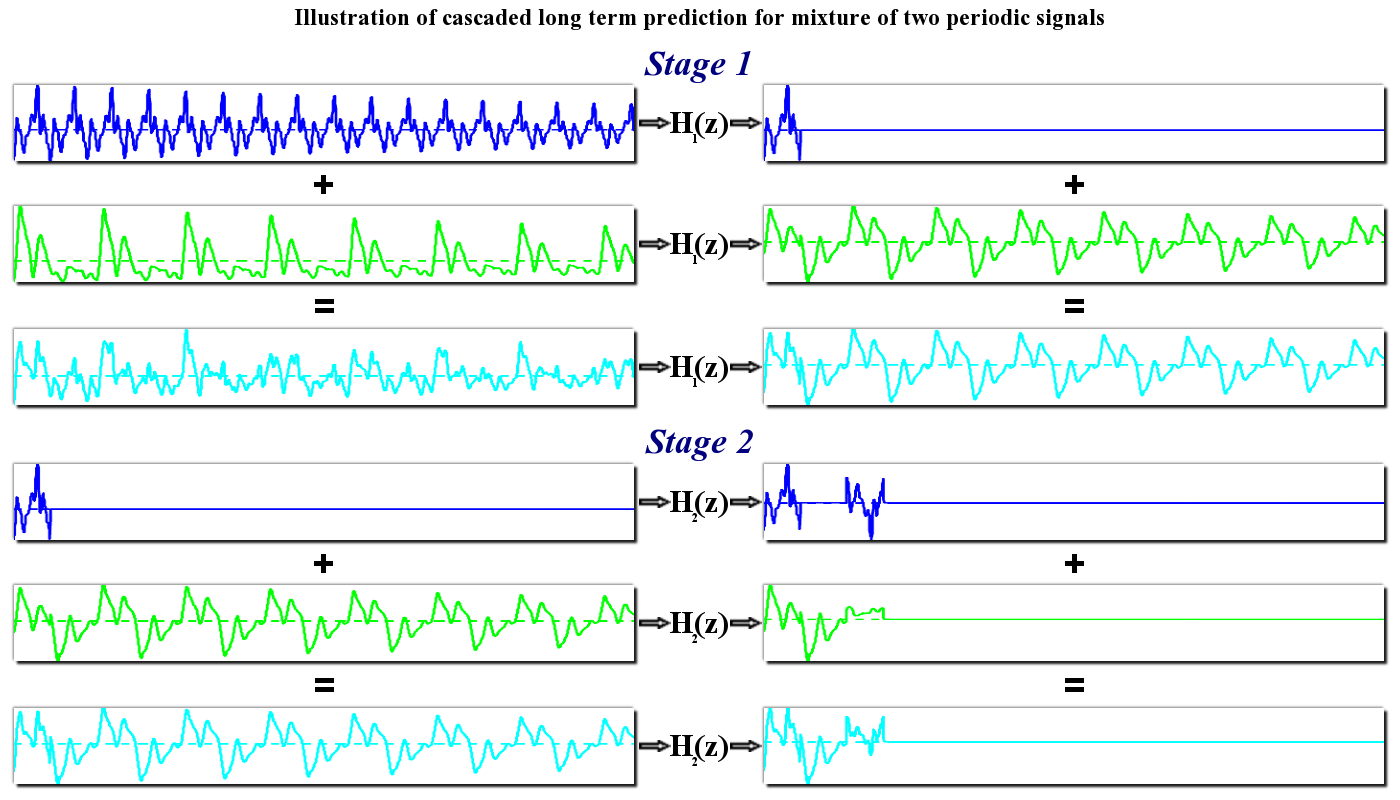
Cascaded long term prediction for coding polyphonic audio signals:
The currently available LTP tool assumes presence of a simple single periodic component in the audio signal, whereas, most audio signals are polyphonic in nature containing a mixture of several periodic components. While such polyphonic signals are themselves periodic with overall period equaling the least common multiple of the individual component periods, the LTP tool is suboptimal in this case, as the signal rarely remains sufficiently stationary over the extended period. Instead of seeking a past segment that represents a ``compromise'' for incompatible component periods, we propose a more complex filter that caters to the individual signal components. This proposed technique predicts every periodic component of the signal from its immediate history, and this is achieved by cascading LTP (CLTP) filters, each corresponding to individual periodic component. We also propose a recursive ``divide and conquer" technique to estimate the parameters of all the LTP filters. We then propose enhancing perceptual audio coders with CLTP filters which are designed in a two stage method, wherein an initial set of parameters is estimated backward adaptively to minimize the mean squared prediction error, followed by a refinement stage where parameters are adjusted to minimize the perceptual distortion. Objective and subjective results validate the effectiveness of the proposal on a variety of polyphonic signals in the Bluetooth Sub-band coder (SBC) and the MPEG AAC.
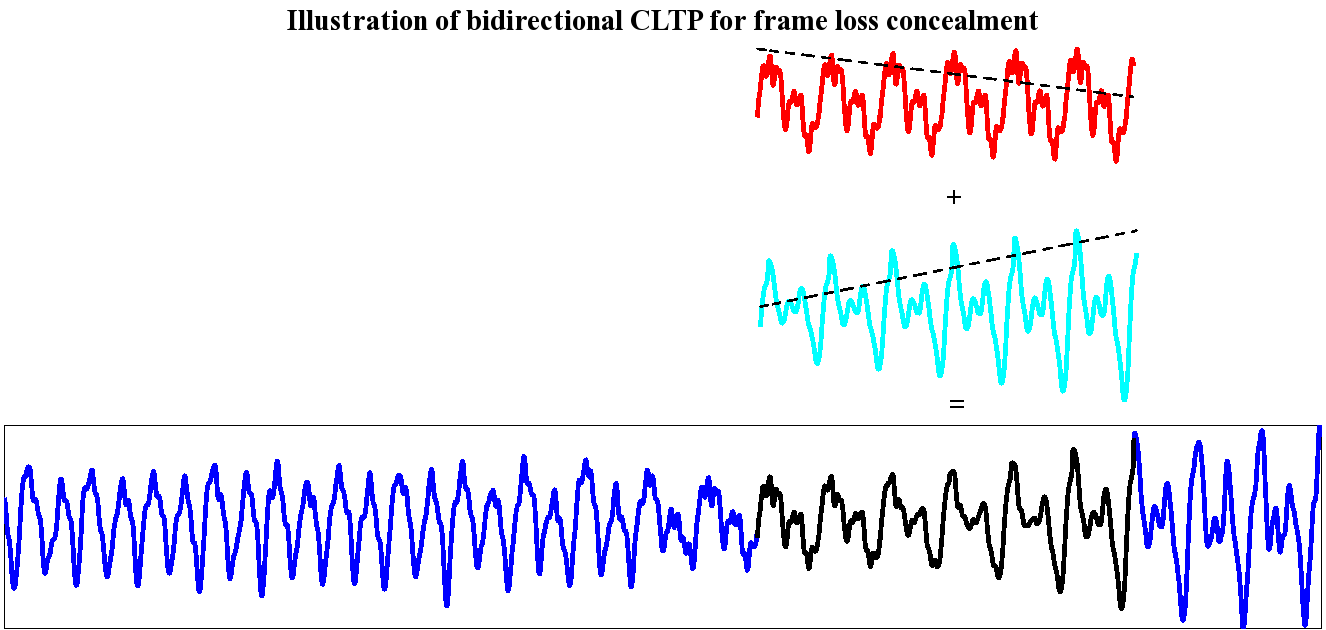
Bidirectional cascaded long term prediction for frame loss concealment in polyphonic audio signals:
We propose a frame loss concealment technique for audio signals, which is designed to overcome the main challenge due to the polyphonic nature of most music signals and is inspired by our previous research on compression of such signals. The underlying idea is to employ a cascade of long term prediction filters (tailored to the periodic components) to circumvent the pitfalls of naive waveform repetition, and to enable effective time-domain prediction of every periodic component from the immediate history. In the first phase, a cascaded filter is designed from available past samples and is used to predict across the lost frame(s). Available future reconstructed samples allow refinement of the filter parameters to minimize the squared prediction error across such samples. In the second phase a prediction is similarly performed in reverse from future samples. Finally the lost frame is interpolated as a weighted average of forward and backward predicted samples. Objective and subjective evaluation results for the proposed approach, in comparison with existing techniques, all incorporated within an MPEG AAC low delay decoder, provide strong evidence for considerable gains across a variety of polyphonic signals.
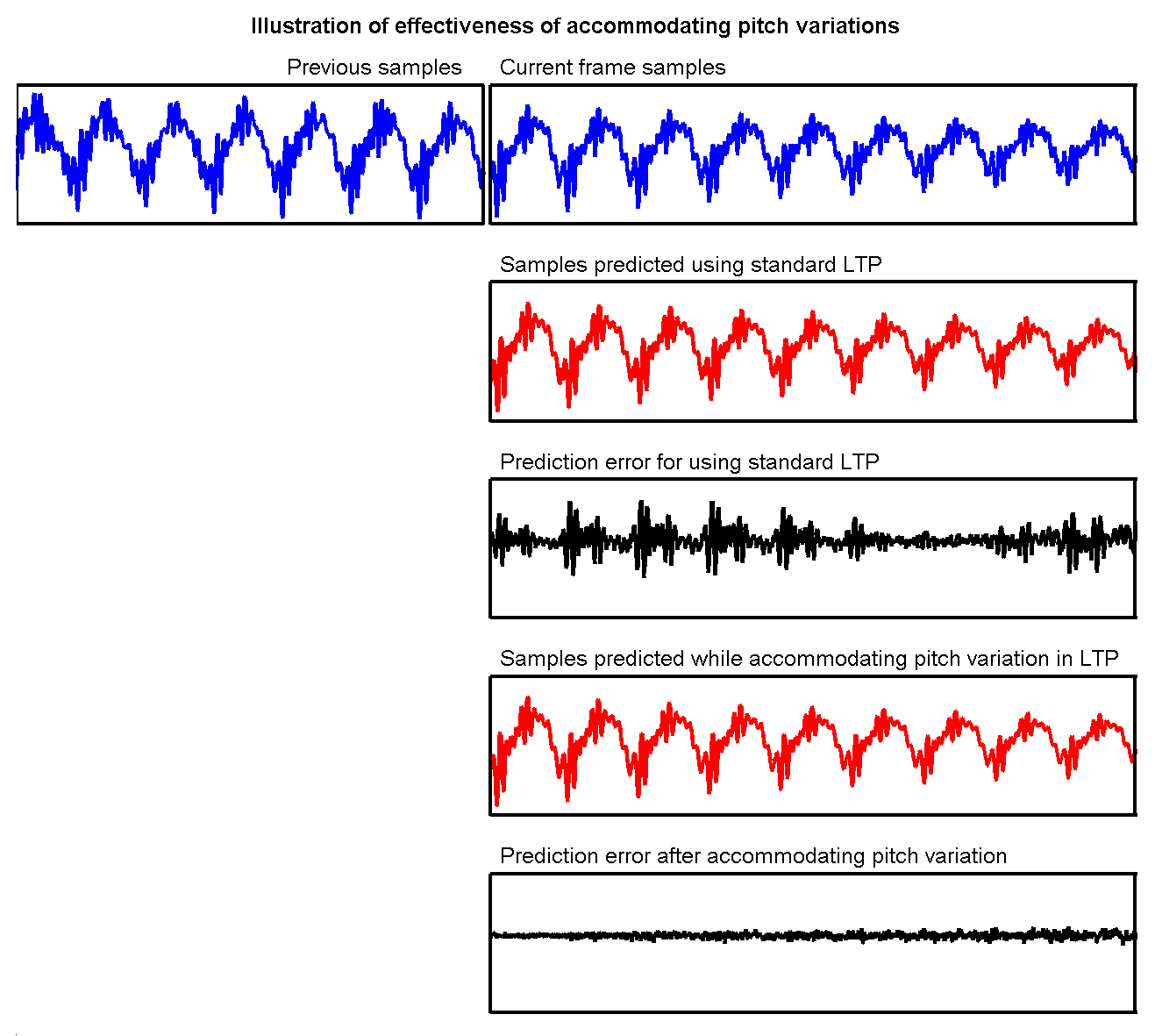
Accommodating pitch variation in long term prediction of speech and vocals in audio coding:
The long term prediction (LTP) tool of MPEG Advanced Audio Coding standard, especially in the low delay mode, capitalizes on the periodicity in naturally occurring sounds by identifying a segment of previously reconstructed data as prediction for the current frame. However, speech and vocal content in audio signals is well known to be quasi-periodic and involve small variations in pitch period, which compromise the LTP tool performance. Thus we propose to modify LTP by introducing a single parameter of ‚"geometric‚" warping, whereby past periodicity is geometrically warped to provide an adjusted prediction for the current samples. We also propose a three-stage parameter estimation technique, where an unwarped LTP filter is first estimated to minimize the mean squared prediction error; then filter parameters are complemented with the warping parameter, and re-estimated within a small neighboring search space to retain the set of S best LTP parameters; and finally, a perceptual distortion-rate procedure is used to select from the S candidates, the parameter set that minimizes the perceptual distortion. Objective and subjective evaluations substantiate the proposed technique's effectiveness.
Cascaded Long Term Prediction of Polyphonic Signals for Low Power Decoders:
An optimized cascade of long term prediction filters, each corresponding to an individual periodic component of the polyphonic audio signal, was shown by us to be highly effective as an inter-frame prediction tool for low delay audio compression. The earlier paradigm involved backward adaptive estimation of most parameters, and hence significantly higher decoder complexity, which is unsuitable for applications that pose a stringent power constraint on the decoder. Thus we propose to overcome this limitation via extension to include forward adaptive parameter estimation, in two modes that trade complexity for side information: i) most parameters are sent as side information and the remaining are backward adaptively estimated; ii) all parameters are sent as side information. We further exploit inter-frame parameter dependencies to minimize the side information rate. Experimental evaluation results clearly demonstrate substantial gains and effective control of the tradeoff between rate-distortion performance and decoder complexity.
The following presentations provide a brief overview of this research direction:
Presentation on accommodating pitch variation in LTP of speech and vocals.
Presentation on bidirectional CLTP for frame loss concealment. [Demo Files]
Presentation on perceptual optimization cascaded LTP for enhanced MPEG AAC. [Demo Files]
Presentation on introduction to cascaded LTP and integration with Bluetooth SBC. [Demo Files]
Presentation on perceptual distortion-Rate optimization of LTP.
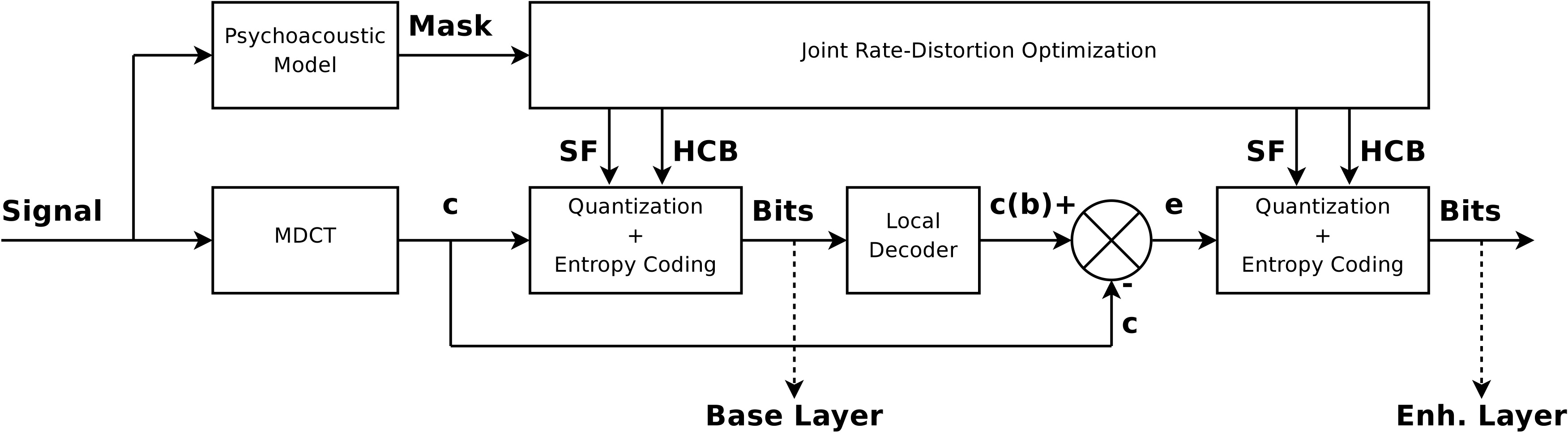
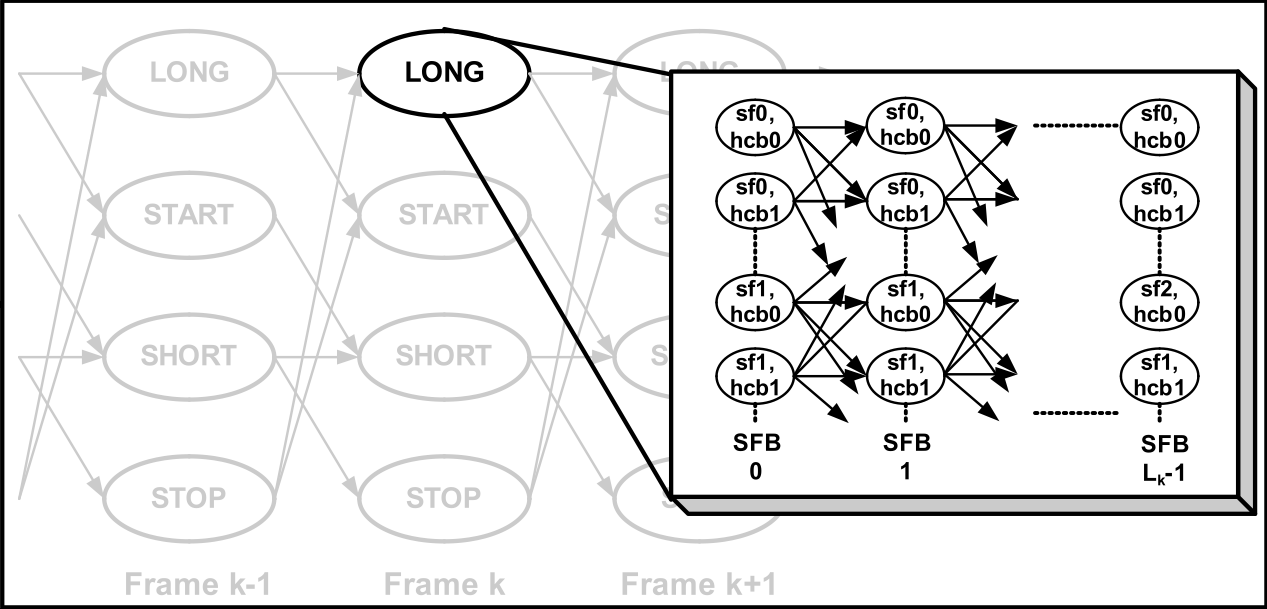 Many important audio coding applications, such as streaming and playback of stored audio, involve offline compression. In such scenarios, encoding delays no longer represent a major concern. Despite this fact, most current audio encoders constrain delay by making encoding decisions on a per frame basis. This sub-project is concerned with delayed-decision approaches to optimize the encoding operation for the audio file. Trellis-based dynamic programming is used for efficient search in the parameter space. A two-layered trellis effectively optimizes the choice of quantization and coding parameters within a frame, as well as window decisions and bit distribution across frames, while minimizing a psychoacoustically relevant distortion measure under a prescribed bit-rate constraint. The bitstream thus produced is standard compatible and there is no additional decoding delay. Objective and subjective results indicate substantial gains over the reference encoder.
Many important audio coding applications, such as streaming and playback of stored audio, involve offline compression. In such scenarios, encoding delays no longer represent a major concern. Despite this fact, most current audio encoders constrain delay by making encoding decisions on a per frame basis. This sub-project is concerned with delayed-decision approaches to optimize the encoding operation for the audio file. Trellis-based dynamic programming is used for efficient search in the parameter space. A two-layered trellis effectively optimizes the choice of quantization and coding parameters within a frame, as well as window decisions and bit distribution across frames, while minimizing a psychoacoustically relevant distortion measure under a prescribed bit-rate constraint. The bitstream thus produced is standard compatible and there is no additional decoding delay. Objective and subjective results indicate substantial gains over the reference encoder. 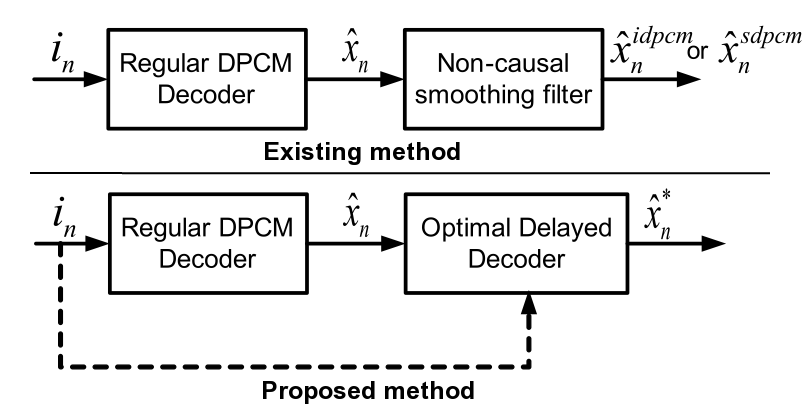 In many upcoming applications of audio and speech coding, such as blue-tooth headsets, advanced hearing-aids, and so on algorithmic delay is a critical issue, in particular when synchronization between the video on display and audio in play-back is the objective. To cater to these delay sensitive applications there is a move towards transform coding with small frame sizes, with prediction employed to exploit inter-frame redundancies. In the extreme case the algorithms could completely eschew transform coding and solely employ predictive signal compression. While the idea is to reduce framing delays to within the limitations posed by the application, delay of just a few samples at the encoder/decoder might be still acceptable.
In many upcoming applications of audio and speech coding, such as blue-tooth headsets, advanced hearing-aids, and so on algorithmic delay is a critical issue, in particular when synchronization between the video on display and audio in play-back is the objective. To cater to these delay sensitive applications there is a move towards transform coding with small frame sizes, with prediction employed to exploit inter-frame redundancies. In the extreme case the algorithms could completely eschew transform coding and solely employ predictive signal compression. While the idea is to reduce framing delays to within the limitations posed by the application, delay of just a few samples at the encoder/decoder might be still acceptable.